
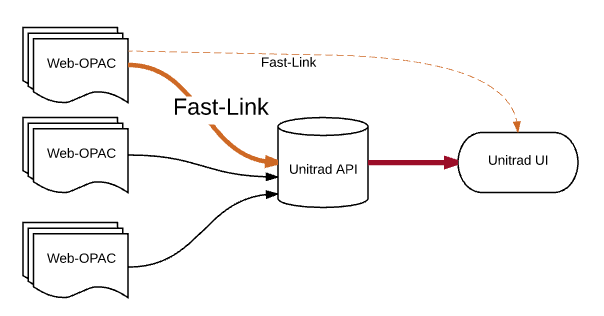
カーリルは、横断検索向け高速連携プロトコル「Unitrad Fast-Link」を提唱し、図書館システムの開発企業と広く協力して革新的なサービスの提供に取り組みます。
Unitrad APIは横断検索システムの効率を飛躍的に向上することで大幅な高速化を実現しました。しかし、各横断検索先とのデータ交換プロトコルには、まだ大きな改善の余地があり、さらなる高速化と効率化が期待できるのです。そのため、各図書館のシステムと効率的にデータ交換できる負担が少なく実用的なプロトコルが求められていました。
今後、オープンソースとして公開した汎用的な蔵書検索インターフェース「Unitrad UI」でもこのプロトコルをサポートすることにより、カーリルのクラウドサービスを通過できない非公開OPACや館内OPACなどでもこのプロトコルの恩恵を受けられるようになる可能性があります。シンプルなプロトコルで実装されたシステムは一般的に速度や安定性が向上するため、長期的にはWeb-OPACの信頼性向上につながります。

基本コンセプト
- 既存の図書館システムの資産を最大限に活用すること
- 最小の開発コストで導入できること
- シンプルであること
- 自由に拡張できること(プロトコルが定めるのは伝送手法と設計ポリシーのみ)
- プロトコルについて一切の権利を主張しないこと(オープン)
Unitrad Fast-Linkの仕様
- 検索結果の書誌1件をJSONフォーマットで表現する
- 書誌と書誌のあいだは改行(”\n”)で区切る(Newline Delimited JSON)
- 効率的な単位(100件程度か500ms)ごとにHTTP Chuckとして逐次送信する(Chunked transfer encoding)
- 常に1件目から送信可能な上限件数まで送信する(ページ指定を禁止する)
- 送信開始時点で該当件数が未確定であることを歓迎する(該当件数の送信を禁止する)
- 各JSONには図書館システム上でその書誌を特定するためのIDを必須とする(プロパティ名ははidとする)
- 各JSONのプロパティ名はtitle,volume,author,publisher,pubdate,isbn,ncid,urlを推奨するが拘束はしない(自由に追加もできる)
- 検索パラメータはGETとする
- 検索パラメータはAND指定のみサポートする
- 検索パラメータはkeyword,title,author,publisher,year_start,year_end,isbn,ncid,classを推奨するが拘束はしない(自由に追加もできる)
- 送信順序はidの降順を推奨するが拘束はしない
- プロパティやパラメータの追加部分については相互互換性を担保する必要はない
(このプロトコルは検索プロトコルでありメタデータ交換プロトコルではない)
実装手法と効果
プロトコルの実装方法は自由です。しかし、しかしプロトコルには設計上の意図が含まれており、それを的確に捉えることで効果的な実装が可能となります。
一般的な図書館システムは、リレーショナルデータベース(OracleやPostgreSQLなど)を基盤として構築されています。そして、簡易的なMARC情報を収めた書誌テーブルと、各資料に貼られたバーコード(資料コード)をキーとする所蔵テーブルに分けられています。
Web-OPACでの検索はSQLに変換されデータベースサーバーで実行されます。このとき、除籍や準備中の資料を検索結果に表示しないようにするために、書誌テーブルと所蔵テーブルをリレーション(連結)したうえでデータの絞り込みが行われます。このようなテーブルのリレーションは所蔵数や条件が多くなると、しばしば致命的な速度の低下を引き起こします。
書誌情報の検索にかかる時間を500ミリ秒、1書誌あたりに表示するかどうかを判定するのにかかる時間を10ミリ秒と仮定した場合、次のような処理時間が必要です。通常は何らかのソート条件を伴いますので、最初の10件を表示する場合でも結局は全件について処理する必要があるのです。(特に公共図書館の場合は、貸出条件が複雑化しており、リレーショナルデータベースではなくロジックコードで判定している場合も多いと考えられます)
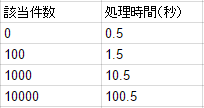

このように、該当件数によってリニアに遅くなる場合、Fast-Linkは有効に機能します。従来のWeb-OPACではページネーションの負荷対策として実装されているセッションやテンポラリファイル、テンポラリテーブルなどの利用を排除してください。ソートはフロンドエンドで実装されるべきです。多くの場合ユーザーは新しい資料を探しているため、書誌IDの降順が推奨されます。ページネーションの実装も不要です。常に該当するデータを可能な限り多く返します。
HTTPのヘッダーに以下の指定をすることで、応答結果を逐次送信できます。検索処理が実行中であっても準備ができた書誌から送信し、それをブラウザに伝送することができます。
Transfer-Encoding: chunked
100件溜まるか500ミリ秒たった時点で、それまでに準備できた検索結果を一度送信します。通常、1ページ目の表示件数は10件~50件程度ですから、先ほどのケースでは1.5秒までには確実に検索結果を表示できます。
このような実装は検索用のインデックスサーバーをもつ大規模な図書館システムにも有効です。データベースで運用される図書館システムに検索インデックスサーバーを組み込む場合、多くの場合でインデックスはバッチ処理により日次で実行し、リアルタイムの所蔵ステータスはデータベースサーバーから取得するといった実装になります。この場合でもはやり件数が多くなるとデータベースへの問い合わせが多く発生し遅延が発生します。しかし、Fast-Linkによる応答の場合には常に高速な結果表示が可能となります。
# 概念実装例(Python)
response.headers['Transfer-Encoding'] = 'chunked'
buffer = []
last_flushed = None
def flush():
for book in buffer:
response.write(json.dumps(book) + "\n")
response.flush()
buffer = []
last_flushed = time.time()
results = search(query)
for book in results:
if is_visible_bib(book.id):
buffer.append(book)
if ((time.time() - last_flushed >= 0.5)
or (!last_flushed and len(buffer)>100)):
flush(buffer)
flush(buffer)
リレーションを多用した複雑なSQLを、検索と所蔵確認(結果を表示するかどうか)という2つのロジックに分割してください。全体の処理時間は増加するかもしれませんが、結果表示までの時間は大幅に短縮することができます。また時間のかかるデータベースクエリが減ることによりデータベースサーバーの並行性が高まり処理効率は大幅に改善します。結果として、ユーザー体験の品質を確実に向上させることができます。
バッファの送信時にエラー検出することで、ユーザーが途中で切断した場合などの無駄な処理を減らすことができますが、多くの場合この節約はほとんど節約にならないため、考慮する必要はありません。
応答に該当件数は含みません。該当件数を数え上げるためにはすべての該当書誌について所蔵確認をする必要があるため効率が悪くなります。
HTTP Chunked TransferとJSON New Linesを用いた逐次送信だけで伝送効率は大幅に改善されるためここに書いたロジックをすべて実装する必要はありません。なおHTTP/2での実装については今後の検討課題であり現時点ではHTTP/1.1をサポートしています。そのため、プロキシ―サーバーなどによりプロトコル改変を伴う中継が行われた場合はメリットを享受することはできません。(ただし通常のHTTP通信にフォールバックされるためエラーにはならないはずです。)
このプロトコルは今後、メーカーとの協力により実際の図書館システムに組み込むことにより有効性を検証していきます。
なぜ標準的なプロトコルではないのか
私たちがこのプロトコルに取り組むのは決して速度を重視しているからではありません。OpenSearchのような標準的な検索プロトコルとの大きな違いは、共通化のための「メタデータマッピング」の作業を伴わないことです。メタデータマッピングはしばしば破壊的な情報の劣化を引き起こしてきました。とくに公共図書館や専門図書館のように図書館員がメタデータマッピングに深い関与ができない環境ではこの問題は致命的です。図書館がAPIを整備しても結局は利用者側で個別の調整が必要であり、多くの場合は正しいデータが取得することができませんでした。そのためカーリルでは、図書館がAPIを整備している場合でもほとんどのケースでWeb-OPACのスクレイピングを信頼しています。何故ならWeb-OPACは常に図書館員によって確認されているからです。
こうした経緯を考えれば、メタデータマッピングはメタデータを整理するアグリゲーター(カーリルや都道府県立図書館、あるいは国立国会図書館など)の責任によって行われるべきであり、各図書館は自らの図書館が扱う合理的なデータを配信するべきです。
Web-OPACで扱うデータをそのままデータとして出力することは、運用上も直感的です。そのため最終的にはWeb-OPACや館内OPACでもFast-Linkを活用することができるのです。プロトコルのプロパティは自由に追加できるので運用上必要な項目は自由に追加できます。
標準的な検索プロトコルはFast-Linkで扱うデータの変換だけで実現できるようになるため、結果的には標準化を一歩前進することになります。